Teradata QueryGrid provides unprecedented analytic power for data-driven businesses and extends the data lake value of Hadoop.
Organizations are struggling to capture and interpret data that is spread across various analytic systems, each system handling different types of processing and data. Teradata, the analytic data platforms, marketing applications and services company, today delivered the most complete big data solution in the industry with Teradata QueryGrid, the only software that optimizes analytics across the enterprise and beyond.
Organizations are seeking the ability to scale the breadth and sophistication of their data analytics to respond to the demands of business operations. The challenge is how to best orchestrate a wide variety of new analytic engines, file systems, storage techniques, procedural languages and data types into one cohesive, interconnected, and complementary analytic architecture.
"Attempts at federation have been unsuccessful for many reasons. To deliver value from big data, customers should create an architecture that allows the orchestration of analytic processes across parallel databases rather than federated servers. Teradata QueryGrid is the most flexible solution with innovative software that gets the job done," said Scott Gnau, president, Teradata Labs. "After the user selects an analytic engine and a file system, Teradata software seamlessly orchestrates analytic processing across systems with a single SQL query, without moving the data. In addition, Teradata allows for multiple file systems and engines in the same workload."
"Teradata pioneered integration with Hadoop and HCatalog with Aster SQL-H to empower customers to run advanced analytics directly on vast amounts of data stored in Hadoop," said Ari Zilka, CTO, Hortonworks. "Now they are taking it to the next level with pushdown processing into Hadoop, leveraging the Hive performance improvements from Hortonworks’ Stinger initiative, delivering results at unprecedented speed and scale."
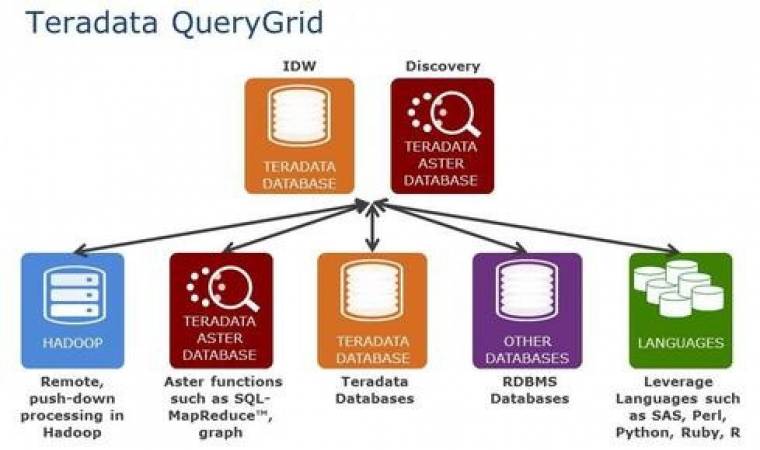
Teradata QueryGrid changes the rules of the game by giving users seamless, self-service access to data and analytic processing across different systems from within a single Teradata Database or Aster Database query. Teradata QueryGrid uses analytic engines and file systems to concentrate their power on accessing and analyzing data without special tools or IT intervention. It minimizes data movement and duplication by processing data where it resides.
Teradata Database 15, with QueryGrid capability, offers bi-directional data movement and pushdown processing to open-source Hadoop, Teradata Aster, and other databases. Queries can be initiated from the Teradata Database to access, filter, and return subsets of data from Hadoop, Aster, and other database environments to the Teradata Database for additional processing. The analysis can incorporate data from the Teradata Database and Hadoop.
The Teradata Unified Data Architecture, which brings together the Teradata Database, Teradata Aster Discovery Platform, and Hadoop technology, makes it possible for Teradata QueryGrid to extend and enrich Teradata and Aster queries, providing users with robust insights.
Users that leverage the Teradata Database and Teradata Aster Discovery Platform benefit from Teradata QueryGrid’s bi-directional data movement and pushdown analytic processing. Teradata’s future vision includes creation of sophisticated options that can connect analytic engines and file systems, which extend processing across the enterprise.
Teradata QueryGrid capabilities will be available in the third quarter of 2014.
